|
5.6.5 probléma: Nemzetekkel kapcsolatos sztereotípiák vizsgálata klaszteranalízissel válaszadó által megadott távolságmátrixok alapján
Az eddig bemutatott példák mindegyikében nyers adatokból indultunk ki. Ezekben az esetekben a személyek valamilyen jellemzők alapján megítélték az elemzéshez használt objektumokat, majd az egyes értékítéletek alapján számoltunk távolságmátrixot. Ám előfordulhat egy olyan megoldás is, amikor nem adunk meg semmi szempontot az értékítéletekhez, csupán azt kérjük, hogy adják meg, szerintük mennyire hasonlóak vagy eltérőek az egyes objektumok. Ennek egy tipikus példája, amikor az egyes nemzeteket ítélik meg hasonlósági/különbözőségi szempontok alapján. Ilyenkor - feltehetően - az emberek támpontok és ismeretek hiányában a saját sztereotípiáikra támaszkodnak.
| |
|
német |
angol |
spanyol |
olasz |
portugál |
holland |
| német |
0 |
|
|
|
|
|
| angol |
4 |
0 |
|
|
|
|
| spanyol |
6 |
7 |
0 |
|
|
|
| olasz |
6 |
6 |
2 |
0 |
|
|
| portugál |
7 |
6 |
1 |
3 |
0 |
|
| holland |
2 |
3 |
7 |
5 |
6 |
0 |
|
|
| |
5.10. táblázat. |
|
Az 5.10. táblázat egy távolságmátrixot mutat. A táblázat egyetlen személy vélekedését mutatja az adott nemzetek különbözőségét illetően. A 0 érték azt jelenti, hogy a két nemzet teljesen megegyezik, míg a 7-es érték azt jelzi, hogy a két nemzet teljes mértékben különbözik egymástól.
d<-
data.frame(német=c(0,4,6,6,7,2),angol=c(4,0,7,6,6,3),spanyol=c(6,7,0,2,1,7),
olasz=c(6,6,2,0,3,5),portugál=c(7,6,1,3,0,6),holland=c(2,3,7,5,6,0))
|
| |
5.33. R-forráskód
|
Első lépése az elemzésnek az adatok bevitele az 5.33. R-forráskód alapján.
név=c("német","angol","spanyol","olasz","portugál","holland")
rownames(d)<-név
|
| |
5.34. R-forráskód
|
Ezt követően az 5.34. R-forráskód segítségével elnevezzük a sorokat is. A kapott szimmetrikus mátrixot az 5.34. R-eredmény mutatja.
német angol spanyol olasz portugál holland
német 0 4 6 6 7 2
angol 4 0 7 6 6 3
spanyol 6 7 0 2 1 7
olasz 6 6 2 0 3 5
portugál 7 6 1 3 0 6
holland 2 3 7 5 6 0
|
| |
5.34. R-eredmény.
|
Ezután meg kell mondani a statisztikai programnak, hogy tekintse az 5.34. R-eredményen látható mátrixot távolságmátrixnak (5.34. R-forráskód és R-eredmény).
német angol spanyol olasz portugál
angol 4
spanyol 6 7
olasz 6 6 2
portugál 7 6 1 3
holland 2 3 7 5 6
|
| |
5.35. R-eredmény.
|
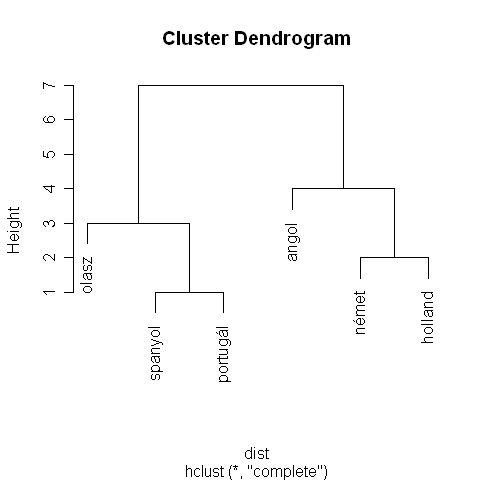
Ez elemzés utolsó lépése a tényleges hierarchikus klaszteranalízis lefuttatása (5.36. R-forráskód). Az 5.36. R-eredményen láthatjuk a kapott dendrogramot. A dendrogramon láthatjuk, hogy kérdezett személy szerint két klaszter létezik. A spanyolok és a portugálok állnak egymáshoz a legközelebb, ezután következnek a hollandok és a németek. Az olaszok a portugál-spanyol klaszterhez csatlakoznak, majd kissé távolabb az angolok a holland-némethez.
|